Hands-on #5: サーバーレス入門
Author:Anda Toshiki
Updated:3 months ago
Words:2.4k
Reading:10 min
前章ではサーバーレスアーキテクチャの概要の説明を行った. 本章では,ハンズオン形式でサーバーレスクラウドを実際に動かしながら,具体的な使用方法を学んでいこう. 今回のハンズオンでは Lambda, S3, DynamoDB の三つのサーバーレスクラウドの構成要素に触れていく. それぞれについて,短いチュートリアルを用意してある.
Lambda ハンズオン
まずは, Lambda を実際に動かしてみよう. ハンズオンのソースコードは GitHub の handson/serverless/lambda に置いてある.
このハンズオンで使用するアプリケーションのスケッチを figure_title に示す. STEP 1 では,AWS CDK を使用して Python で書かれたコードを Lambda に登録する. 続いて STEP 2 では, Invoke API を使用して,同時にいくつもの Lambda を起動し,並列な計算を行う. Lambda のワークフローを体験する目的で最小限の設定である.
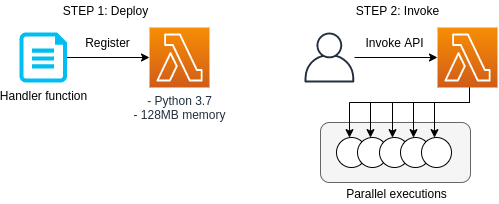
このハンズオンは,基本的に AWS Lambda の無料枠 の範囲内で実行することができる.
app.py にデプロイするプログラムが書かれている. 中身を見てみよう.
python
#
FUNC = """
import time
from random import choice, randint
def handler(event, context):
time.sleep(randint(2,5))
sushi = ["salmon", "tuna", "squid"]
message = "Welcome to Cloud Sushi. Your order is " + choice(sushi)
print(message)
return message
"""
class SimpleLambda(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
#
handler = _lambda.Function(
self, 'LambdaHandler',
runtime=_lambda.Runtime.PYTHON_3_7,
code=_lambda.Code.from_inline(FUNC),
handler="index.handler",
memory_size=128,
timeout=core.Duration.seconds(10),
dead_letter_queue_enabled=True,
)#
FUNC = """
import time
from random import choice, randint
def handler(event, context):
time.sleep(randint(2,5))
sushi = ["salmon", "tuna", "squid"]
message = "Welcome to Cloud Sushi. Your order is " + choice(sushi)
print(message)
return message
"""
class SimpleLambda(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
#
handler = _lambda.Function(
self, 'LambdaHandler',
runtime=_lambda.Runtime.PYTHON_3_7,
code=_lambda.Code.from_inline(FUNC),
handler="index.handler",
memory_size=128,
timeout=core.Duration.seconds(10),
dead_letter_queue_enabled=True,
)ここで, Lambda で実行されるべき関数を定義している. これは非常に単純な関数で,2-5 秒のランダムな時間スリープした後,["salmon", "tuna", "squid"] のいずれかの文字列をランダムに選択し, "Welcome to Cloud Sushi. Your order is XXXX" (XXXX は選ばれた寿司のネタ) というメッセージをリターンする.
次に, Lambda に <1> で書いた関数を配置している. パラメータの意味は,文字どおりの意味なので難しくはないが,以下に解説する.
runtime=_lambda.Runtime.PYTHON_3_7: ここでは, Python3.7 を使って上記で定義された関数を実行せよ,と指定している. Python3.7 のほかに, Node.js, Java, Ruby, Go などの言語を指定することが可能である.code=_lambda.Code.from_inline(FUNC): 実行されるべき関数が書かれたコードを指定する. ここでは,FUNC=...で定義した文字列を渡しているが,文字列以外にもファイルのパスを渡すことも可能である.handler="index.handler": これは,コードの中にいくつかのサブ関数が含まれているときに,メインとサブを区別するためのパラメータである.handlerという名前の関数をメイン関数として実行せよ,という意味である.memory_size=128: メモリーは 128MB を最大で使用することを指定している.timeout=core.Duration.seconds(10)タイムアウト時間を 10 秒に設定している. 10 秒以内に関数の実行が終了しなかった場合,エラーが返される.dead_letter_queue_enabled=True: アドバンストな設定なので説明は省略する.
上記のプログラムを実行することで, Lambda 関数がクラウド上に作成される. 早速デプロイしてみよう.
デプロイ
デプロイの手順は,これまでのハンズオンとほとんど共通である. ここでは,コマンドのみ列挙する (# で始まる行はコメントである). それぞれの意味を忘れてしまった場合は,ハンズオン 1, 2 に戻って復習していただきたい. シークレットキーの設定も忘れずに ( (#aws_cli_install)).
sh
# プロジェクトのディレクトリに移動
$ cd handson/serverless/lambda
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deploy# プロジェクトのディレクトリに移動
$ cd handson/serverless/lambda
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deployデプロイのコマンドが無事に実行されれば, figure_title のような出力が得られるはずである. ここで表示されている SimpleLambda.FunctionName = XXXX の XXXX の文字列は後で使うのでメモしておこう.

AWS コンソールにログインして,デプロイされたスタックを確認してみよう. コンソールから,Lambda のページに行くと figure_title のような画面から Lambda の関数の一覧が確認できる.
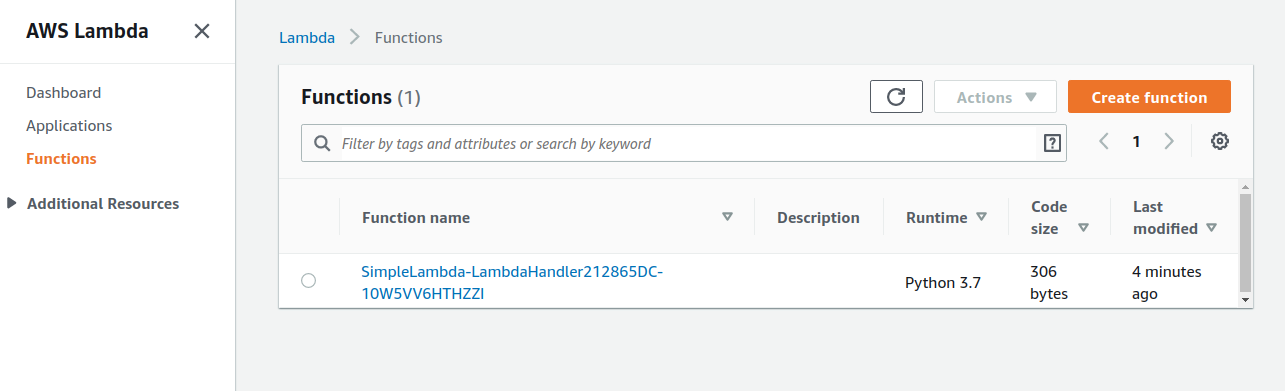
今回のアプリケーションで作成したのが SimpleLambda で始まるランダムな名前のついた関数だ. 関数の名前をクリックして,詳細を見てみる. すると figure_title のような画面が表示されるはずだ. 先ほどプログラムの中で定義した Python の関数がエディターから確認できる. さらに下の方にスクロールすると,関数の各種設定も確認できる.
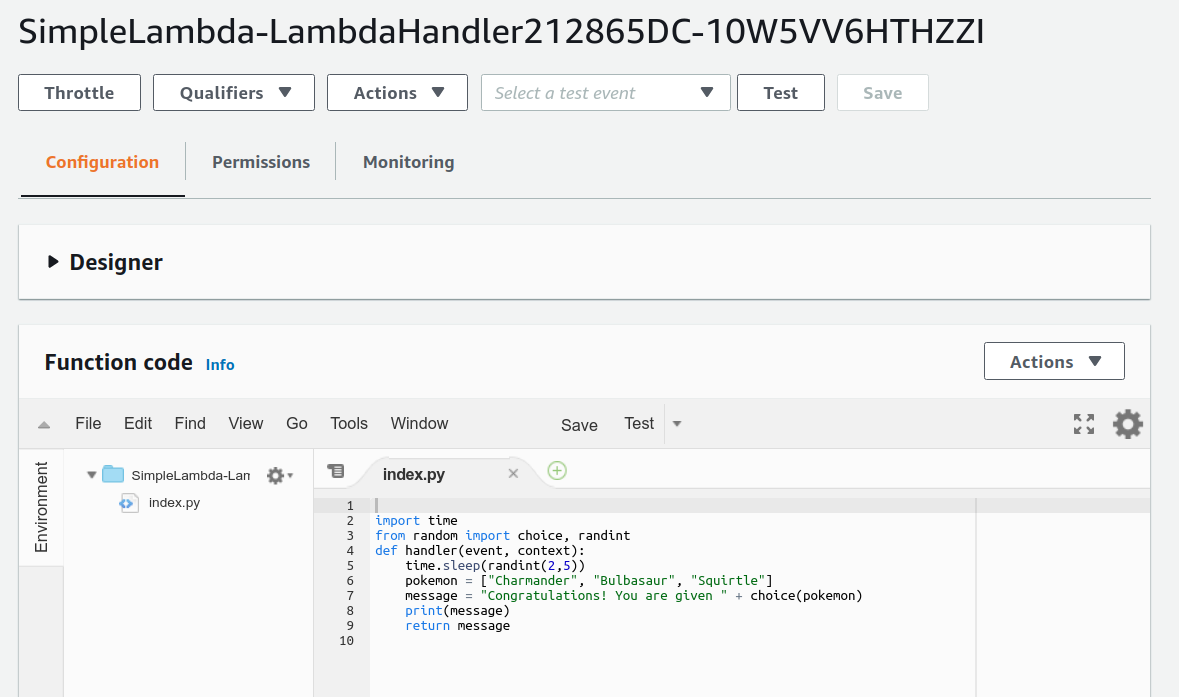
Lambda で実行されるコードは, Lambda のコンソール画面 (figure_title) のエディターで編集することもできる. デバッグをするときなどは,こちらを直接いじる方が早い場合もある. その場合は, CDK のコードに行った編集を反映させなおすことを忘れずに.
Lambda 関数の実行
それでは,作成した Lambda 関数を実行 (invoke) してみよう. AWS の API を使うことで,関数の実行をスタートすることができる. 今回は, handson/serverless/lambda/invoke_one.py に関数を実行するための簡単なプログラムを提供している. 興味のある読者はコードを読んでもらいたい.
以下のコマンドで,Lambda の関数を実行する. コマンドの XXXX の部分は,先ほどデプロイしたときに SimpleLambda.FunctionName = XXXX で得られた XXXX の文字列で置換する.
sh
$ python invoke_one.py XXXX$ python invoke_one.py XXXXすると, "Welcome to Cloud Sushi. Your order is salmon" という出力が得られるはずだ. とてもシンプルではあるが,クラウド上で先ほどの関数が走り,乱数が生成されたうえで,ランダムな寿司ネタが選択されて出力が返されている. このコマンドを何度か打ってみて,実行ごとに異なる寿司ネタが返されることを確認しよう.
さて,このコマンドは,一度につき一回の関数を実行したわけであるが, Lambda の本領は一度に大量のタスクを同時に実行できる点である. そこで,今度は一度に 100 個のタスクを同時に送信してみよう. handson/serverless/lambda/invoke_many.py のスクリプトを使用する.
次のコマンドを実行しよう. XXXX の部分は前述と同様に置き換える. 第二引数の 100 は 100 個のタスクを投入せよ,という意味である.
sh
$ python invoke_many.py XXXX 100$ python invoke_many.py XXXX 100すると次のような出力が得られるはずだ.
sh
....................................................................................................
Submitted 100 tasks to Lambda!....................................................................................................
Submitted 100 tasks to Lambda!実際に,100 個のタスクが同時に実行されていることを確認しよう. figure_title の画面に戻り, "Monitoring" というタブがあるので,それをクリックする. すると, figure_title のようなグラフが表示されるだろう.
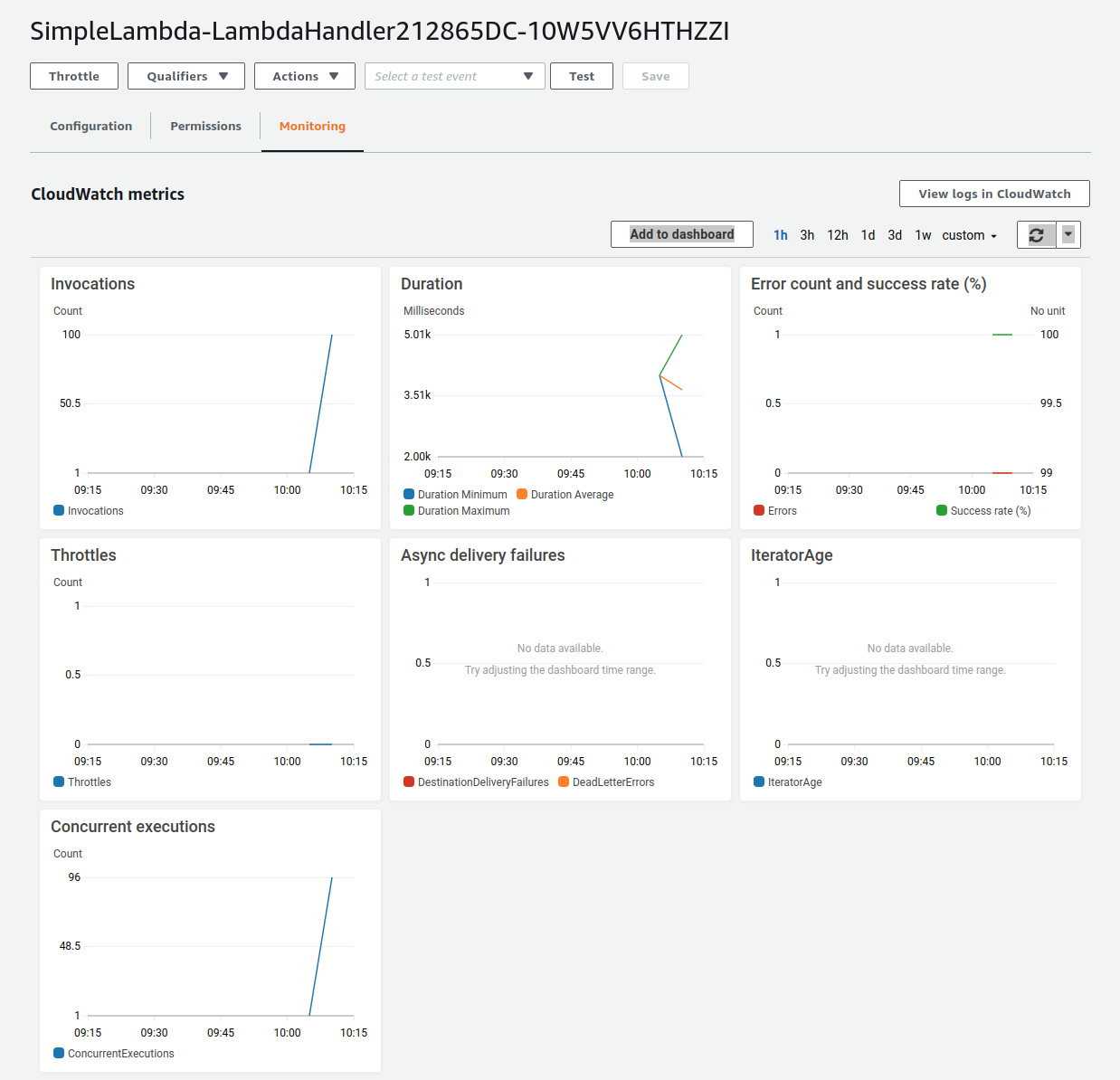
figure_title のグラフの更新には数分かかることがあるので,なにも表示されない場合は少し待つ.
figure_title で "Invocations" が関数が何度実行されたかを意味している. たしかに 100 回実行されていることがわかる. さらに, "Concurrent executions" は何個のタスクが同時に行われたかを示している. ここでは 96 となっていることから,96 個のタスクが並列的に実行されたことを意味している (これが 100 とならないのは,タスクの開始のコマンドが送られたのが完全には同タイミングではないことに起因する).
このように,非常にシンプルではあるが, Lambda を使うことで,同時並列的に処理を実行することのできるクラウドシステムを簡単に作ることができた.
もしこのようなことを従来的な serverful なクラウドで行おうとした場合,クラスターのスケーリングなど多くのコードを書くことに加えて,いろいろなパラメータを調節する必要がある.
興味がある人は,一気に 1000 個などのジョブを投入してみるとよい. Lambda はそのような大量のリクエストにも対応できることが確認できるだろう. が,あまりやりすぎると Lambda の無料利用枠を超えて料金が発生してしまうので注意.
スタックの削除
最後にスタックを削除しよう. スタックを削除するには,次のコマンドを実行すればよい.
sh
$ cdk destroy$ cdk destroyDynamoDB ハンズオン
続いて, DynamoDB の簡単なチュートリアルをやってみよう. ハンズオンのソースコードは GitHub の /handson/serverless/dynamodb に置いてある.
このハンズオンで使用するアプリケーションのスケッチを figure_title に示す. STEP 1 では,AWS CDK を使用して DynamoDB のテーブルを初期化し,デプロイする. 続いて STEP 2 では, API を使用してデータベースのデータの書き込み・読み出し・削除などの操作を練習する.
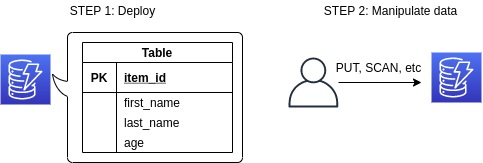
このハンズオンは,基本的に AWS DynamoDB の無料枠 の範囲内で実行できる.
handson/serverless/dynamodb/app.py にデプロイするプログラムが書かれている. 中身を見てみよう.
python
class SimpleDynamoDb(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
table = ddb.Table(
self, "SimpleTable",
#
partition_key=ddb.Attribute(
name="item_id",
type=ddb.AttributeType.STRING
),
#
billing_mode=ddb.BillingMode.PAY_PER_REQUEST,
#
removal_policy=core.RemovalPolicy.DESTROY
)class SimpleDynamoDb(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
table = ddb.Table(
self, "SimpleTable",
#
partition_key=ddb.Attribute(
name="item_id",
type=ddb.AttributeType.STRING
),
#
billing_mode=ddb.BillingMode.PAY_PER_REQUEST,
#
removal_policy=core.RemovalPolicy.DESTROY
)このコードで,最低限の設定がなされた空の DynamoDB テーブルが作成される. それぞれのパラメータの意味を簡単に解説しよう.
partition_key: すべての DynamoDB テーブルには Partition key が定義されていなければならない. Partition key とは,テーブル内の要素 (レコード) ごとに存在する固有の ID のことである. 同一の Partition key をもった要素がテーブルの中に二つ以上存在することはできない (注: Sort Key を使用している場合は除く.詳しくは 公式ドキュメンテーション "Core Components of Amazon DynamoDB" 参照). また, Partition key が定義されていない要素はテーブルの中に存在することはできない. ここでは, Partition key にitem_idという名前をつけている.billing_mode:ddb.BillingMode.PAY_PER_REQUESTを指定することで, On-demand Capacity Mode の DynamoDB が作成される. ほかにPROVISIONEDというモードがあるが,これはかなり高度なケースを除いて使用しないだろう.removal_policy: CloudFormation のスタックが消去されたときに, DynamoDB も一緒に消去されるかどうかを指定する. このコードではDESTROYを選んでいるので,すべて消去される. ほかのオプションを選択すると,スタックを消去しても DynamoDB のバックアップを残す,などの動作を定義することができる.
デプロイ
デプロイの手順は,これまでのハンズオンとほとんど共通である. ここでは,コマンドのみ列挙する (# で始まる行はコメントである). シークレットキーの設定も忘れずに ( (#aws_cli_install)).
sh
# プロジェクトのディレクトリに移動
$ cd handson/serverless/dynamodb
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deploy# プロジェクトのディレクトリに移動
$ cd handson/serverless/dynamodb
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deployデプロイのコマンドが無事に実行されれば, figure_title のような出力が得られるはずである. ここで表示されている SimpleDynamoDb.TableName = XXXX の XXXX の文字列は後で使うのでメモしておこう.

AWS コンソールにログインして,デプロイされたスタックを確認してみよう. コンソールから, DynamoDB のページに行き,左のメニューバーから "Tables" を選択する. すると, figure_title のような画面からテーブルの一覧が確認できる.
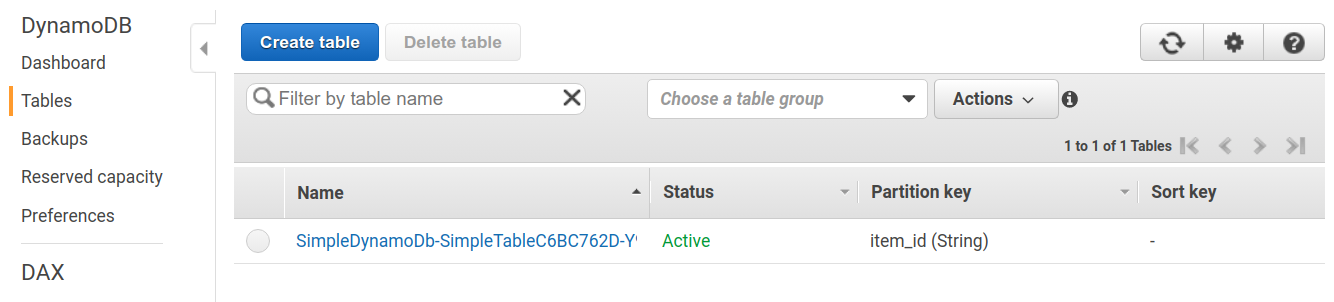
今回のアプリケーションで作成したのが SimpleDynamoDb で始まるランダムな名前のついたテーブルだ. テーブルの名前をクリックして,詳細を見てみる. すると figure_title のような画面が表示されるはずだ. "Items" のタブをクリックすると,テーブルの中のレコードを確認できる. 現時点ではなにもデータを書き込んでいないので,空である.
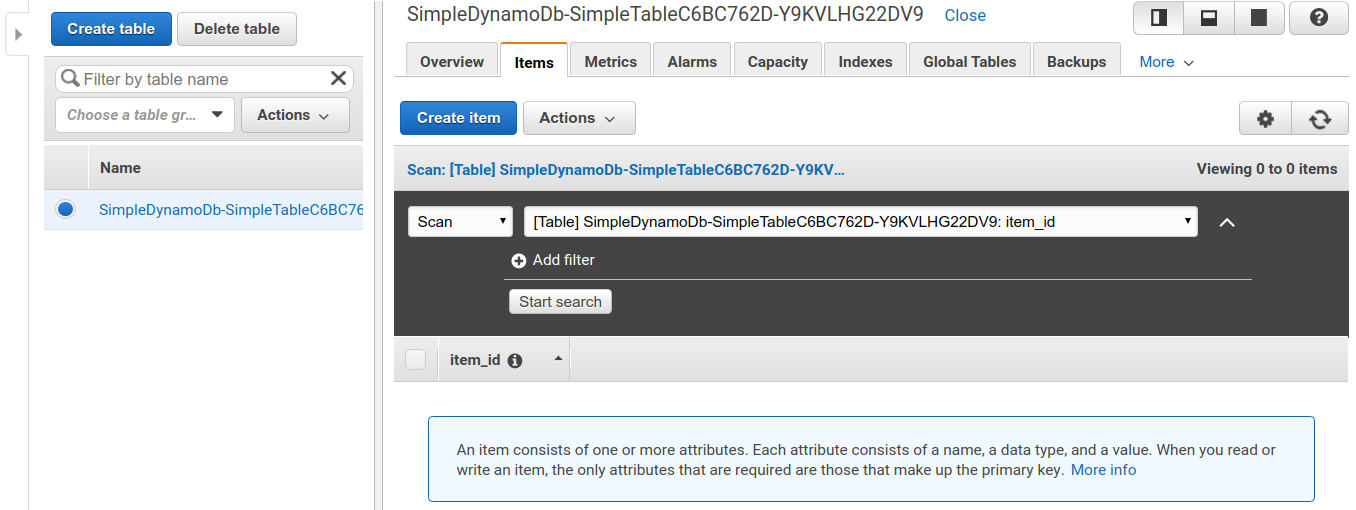
データの読み書き
それでは, デプロイ で作ったテーブルを使ってデータの読み書きを実践してみよう. ここでは Python と boto3 ライブラリを用いた方法を紹介する.
まずは,テーブルに新しい要素を追加してみよう. ハンズオンのディレクトリにある simple_write.py を開いてみよう. 中には次のような関数が書かれている.
python
import boto3
from uuid import uuid4
ddb = boto3.resource('dynamodb')
def write_item(table_name):
table = ddb.Table(table_name)
table.put_item(
Item={
'item_id': str(uuid4()),
'first_name': 'John',
'last_name': 'Doe',
'age': 25,
}
)import boto3
from uuid import uuid4
ddb = boto3.resource('dynamodb')
def write_item(table_name):
table = ddb.Table(table_name)
table.put_item(
Item={
'item_id': str(uuid4()),
'first_name': 'John',
'last_name': 'Doe',
'age': 25,
}
)コードを上から読んでいくと,まず最初に boto3 ライブラリをインポートし, dynamodb のリソースを呼び出している. write_item() 関数は, DynamoDB のテーブルの名前 (上で見た SimpleDynamoDb-XXXX) を引数として受け取る. そして, put_item() メソッドを呼ぶことで,新しいアイテムを DB に書き込んでいる. アイテムには item_id, first_name, last_name, age の 4 つの属性が定義されている. ここで, item_id は先ほど説明した Partition key に相当しており, UUID4 を用いたランダムな文字列を割り当てている.
では, simple_write.py を実行してみよう. "XXXX" の部分を自分がデプロイしたテーブルの名前 (SimpleDynamoDb で始まる文字列) に置き換えたうえで,次のコマンドを実行する.
sh
$ python simple_write.py XXXX$ python simple_write.py XXXX新しい要素が正しく書き込めたか, AWS コンソールから確認してみよう. figure_title と同じ手順で,テーブルの中身の要素の一覧を表示する. すると figure_title のように,期待通り新しい要素が見つかるだろう.
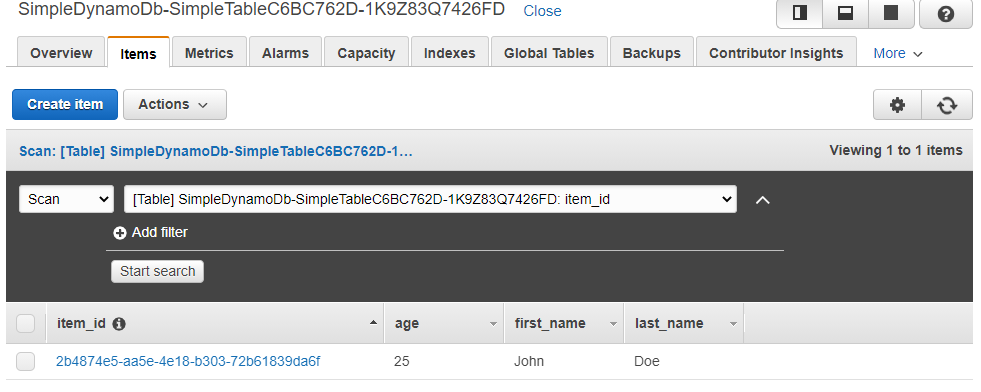
boto3 を使ってテーブルから要素を読みだすことも可能である. ハンズオンのディレクトリにある simple_read.py を見てみよう.
python
import boto3
ddb = boto3.resource('dynamodb')
def scan_table(table_name):
table = ddb.Table(table_name)
items = table.scan().get("Items")
print(items)import boto3
ddb = boto3.resource('dynamodb')
def scan_table(table_name):
table = ddb.Table(table_name)
items = table.scan().get("Items")
print(items)table.scan().get("Items") によって,テーブルの中にあるすべての要素を読みだしている.
次のコマンドで,このスクリプトを実行してみよう ("XXXX" の部分を正しく置き換えることを忘れずに).
sh
$ python simple_read.py XXXX$ python simple_read.py XXXX先ほど書き込んだ要素が出力されることを確認しよう.
大量のデータの読み書き
DynamoDB の利点は,最初に述べたとおり,負荷に応じて自在にその処理能力を拡大できる点である.
そこで,ここでは一度に大量のデータを書き込む場合をシミュレートしてみよう. batch_rw.py に,一度に大量の書き込みを実行するためのプログラムが書いてある.
次のコマンドを実行してみよう (XXXX は自分のテーブルの名前に置き換える).
sh
$ python batch_rw.py XXXX write 1000$ python batch_rw.py XXXX write 1000このコマンドを実行することで,ランダムなデータが 1000 個データベースに書き込まれる.
さらに,データベースの検索をかけてみよう. 今回書き込んだデータには age という属性に 1 から 50 のランダムな整数が割り当てられている. age が 2 以下であるような要素だけを検索し拾ってくるには,次のコマンドを実行すればよい.
sh
$ python batch_rw.py XXXX search_under_age 2$ python batch_rw.py XXXX search_under_age 2上の 2 つのコマンドを何回か繰り返し実行してみて,データベースに負荷をかけてみよう. とくに大きな遅延なく結果が返ってくることが確認できるだろう.
スタックの削除
DynamoDB で十分に遊ぶことができたら,忘れずにスタックを削除しよう.
これまでのハンズオンと同様,スタックを削除するには,次のコマンドを実行すればよい.
sh
$ cdk destroy$ cdk destroyS3 ハンズオン
最後に, S3 の簡単なチュートリアルを紹介する. ハンズオンのソースコードは GitHub の handson/serverless/s3 に置いてある.
figure_title が今回提供する S3 チュートリアルの概要である. STEP 1 として, AWS CDK を用いて S3 に新しい空のバケット (Bucket) を作成する. 続いて STEP 2 では,データのアップロード・ダウンロードの方法を解説する.

このハンズオンは,基本的に S3 の無料枠 の範囲内で実行することができる.
app.py にデプロイするプログラムが書かれている. 中身を見てみよう.
python
class SimpleS3(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
# S3 bucket to store data
bucket = s3.Bucket(
self, "bucket",
removal_policy=core.RemovalPolicy.DESTROY,
auto_delete_objects=True,
)class SimpleS3(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
# S3 bucket to store data
bucket = s3.Bucket(
self, "bucket",
removal_policy=core.RemovalPolicy.DESTROY,
auto_delete_objects=True,
)s3.Bucket() を呼ぶことによって空のバケットが新規に作成される. 上記のコードだと,バケットの名前は自動生成される. もし,自分の指定した名前を与えたい場合は, bucket_name というパラメータを指定すればよい. その際, バケットの名前はユニークでなければならない (i.e. AWS のデプロイが行われるリージョン内で名前の重複がない) 点に注意しよう. もし,同じ名前のバケットが既に存在する場合はエラーが返ってくる.
デフォルトでは, CloudFormation スタックが削除されたとき, S3 バケットとその中に保存されたファイルは削除されない. これは,大切なデータを誤って消してしまうことを防止するための安全策である. cdk destroy を実行したときにバケットも含めてすべて削除されるようにするには, removal_policy=core.RemovalPolicy.DESTROY, auto_delete_objects=True とパラメータを設定する. 結果もよく理解したうえで,自分の用途にあった適切なパラメータを設定しよう.
デプロイ
デプロイの手順は,これまでのハンズオンとほとんど共通である. ここでは,コマンドのみ列挙する (# で始まる行はコメントである). シークレットキーの設定も忘れずに ( (#aws_cli_install)).
sh
# プロジェクトのディレクトリに移動
$ cd handson/serverless/s3
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deploy# プロジェクトのディレクトリに移動
$ cd handson/serverless/s3
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deployデプロイを実行すると, figure_title のような出力が得られるはずである. ここで表示されている SimpleS3.BucketName = XXXX が,新しく作られたバケットの名前である (今回提供しているコードを使うとランダムな名前がバケットに割り当てられる). これはあとで使うのでメモしておこう.

データの読み書き
スタックのデプロイが完了したら,早速バケットにデータをアップロードしてみよう.
まずは,以下のコマンドを実行して, tmp.txt という仮のファイルを生成する.
sh
$ echo "Hello world!" >> tmp.txt$ echo "Hello world!" >> tmp.txtハンズオンのディレクトリにある simple_s3.py に boto3 ライブラリを使用した S3 のファイルのアップロード・ダウンロードのスクリプトが書いてある. simple_s3.py を使って,上で作成した tmp.txt を以下のコマンドによりバケットにアップロードする. XXXX のところは,自分自身のバケットの名前で置き換えること.
sh
$ python simple_s3.py XXXX upload tmp.txt$ python simple_s3.py XXXX upload tmp.txtsimple_s3.py のアップロードを担当している部分を以下に抜粋する.
python
def upload_file(bucket_name, filename, key=None):
bucket = s3.Bucket(bucket_name)
if key is None:
key = os.path.basename(filename)
bucket.upload_file(filename, key)def upload_file(bucket_name, filename, key=None):
bucket = s3.Bucket(bucket_name)
if key is None:
key = os.path.basename(filename)
bucket.upload_file(filename, key)bucket = s3.Bucket(bucket_name) の行で Bucket() オブジェクトを呼び出している. そして, upload_file() メソッドを呼ぶことでファイルのアップロードを実行している.
S3 においてファイルの識別子として使われるのが Key である. これは,従来的なファイルシステムにおけるパス (Path) と相同な概念で,それぞれのファイルに固有な Key が割り当てられる必要がある. Key という呼び方は, S3 が Object storage と呼ばれるシステムに立脚していることに由来する. --key のオプションを追加して simple_s3.py を実行することで, Key を指定してアップロードを実行することができる.
sh
$ python simple_s3.py XXXX upload tmp.txt --key a/b/tmp.txt$ python simple_s3.py XXXX upload tmp.txt --key a/b/tmp.txtここではアップロードされたファイルに a/b/tmp.txt という Key を割り当てている.
ここまでコマンドを実行し終えたところで,一度 AWS コンソールに行き S3 の中身を確認してみよう. S3 のコンソールに行くと,バケットの一覧が見つかるはずである. その中から, simples3-bucket から始まるランダムな名前のついたバケットを探し,クリックする. するとバケットの中に含まれるファイルの一覧が表示される (figure_title).
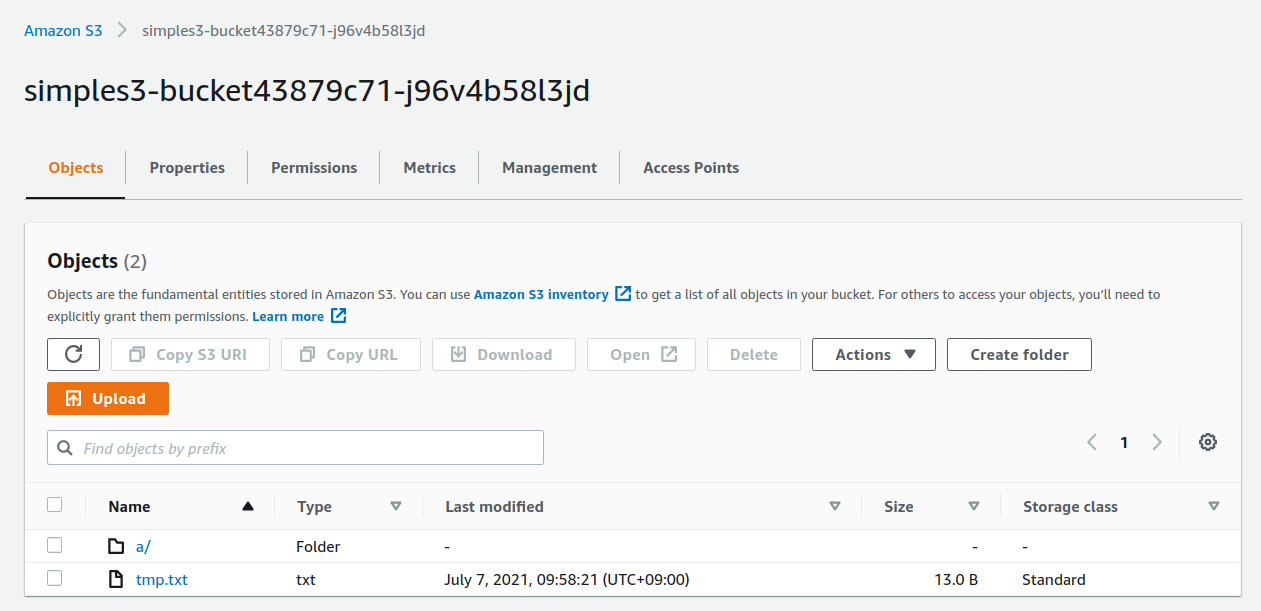
ここで実行した 2 つのコマンドによって, tmp.txt というファイルと, a/b/tmp.txt というファイルが見つかることに注目しよう. 従来的なファイルシステムと似た体験を提供するため, S3 では Key が "/" (スラッシュ) によって区切られていた場合,ツリー状の階層構造によってファイルを管理することができる.
オブジェクトストレージには本来ディレクトリという概念はない. 上で紹介した "/" による階層づけはあくまでユーザー体験向上の目的のお化粧的な機能である.
次に,バケットからファイルのダウンロードを実行してみよう. simple_s3.py を使って,以下のコマンドを実行すればよい. XXXX のところは,自分自身のバケットの名前で置き換えること.
sh
$ python simple_s3.py XXXX download tmp.txt$ python simple_s3.py XXXX download tmp.txtsimple_s3.py のダウンロードを担当している部分を以下に抜粋する.
python
def download_file(bucket_name, key, filename=None):
bucket = s3.Bucket(bucket_name)
if filename is None:
filename = os.path.basename(key)
bucket.download_file(key, filename)def download_file(bucket_name, key, filename=None):
bucket = s3.Bucket(bucket_name)
if filename is None:
filename = os.path.basename(key)
bucket.download_file(key, filename)S3 からのダウンロードはシンプルで, download_file() メソッドを使って,ダウンロードしたい対象の Key を指定すればよい. ローカルのコンピュータでの保存先のパスを 2 個目の引数として渡している.
スタックの削除
以上のハンズオンで, S3 の一番基本的な使い方を紹介した. ここまでのハンズオンが理解できたら,忘れずにスタックを削除しよう. これまでのハンズオンと同様,スタックを削除するには,次のコマンドを実行すればよい.
sh
$ cdk destroy$ cdk destroy